DNN训练与调优过程
机器学习是一个持续迭代改进的过程。一般而言,我们需要先快速的构造一个基本满足需求的系统,得到第一个版本的模型。然后,尽快将其投入到测试或者线上环境中、测试这个模型执行情况、收集观测数据。而后根据观察到的指标情况分析下一步的优化方向,改进得到下一个版本的模型。
那么,在这整论迭代中,有哪些需要我们提前了解的基本思路和方法?deeplearning.ai的第二、三门课的内容,就给我们在以下一些关键点上,做了一些基本的介绍:
- 如何划分样本数据?
- 如何进行调参?
- 如何进行error分析?
- error分析后,如何有针对性的进一步调优模型?
这些基本方法,是一个DNN应用在日常迭代中会经常遇到的问题,是前人工作的经验总结。了解这些基本方法,可以少走许多弯路,具有很强的实践指导价值。
划分样本数据
在收集到众多样本数据后,一般而言,需要将数据分成三个集合:
- Train: 主要用于送入反向传播算法以得到模型,其规模应该是样本中最大的那部分;
- Dev:在验证各种Hyper-parameter或者算法的研发过程中,基于dev集合验证不同hyper-parameter或者算法的效果,进行横向比较;
- Test:用于验证最后模型在真实系统的表现情况
一般而言,dev/test两个集合的分布,应当接近于真实目标环境的数据分布。这样才能确保模型的优化方向与最终的目的相符,不会”跑歪”。另外,在规模上,一般是给train集合留尽量多的数据、给train/dev留足够代表性的数据即可。比如10w条数据,train集合9.6w条,dev和test的集合分别留2k数据。
这里需要注意一个细节,我们只要求dev/test的分布与被测场景一致即可,那为什么对train集合的分布没有这个要求呢?其实主要考虑在于,有些时候收集数据是非常困难的。我们拿不到足够的、符合最终应用场景的数据,这时候就需要通过一些其他手段引入某些新的数据,尽管这些引入的数据分布与目标场景不符。
比如,我们要实现一个识别手机拍摄的”猫”的app。在应用推出前,我们手头上并没有足够的、用手机拍摄的”猫”的图像,但通过爬虫却能够从web抓取到很多。手机拍摄的猫比起web网页中的猫的图片,模糊的、各种”偏斜”角度拍摄的要更多一些,即两个来源的数据的分布是不同的。但我们又很想把web的这些样本图片也用起来,该怎么办呢?答案其实很简单,就是我还是可以把这些数据放入训练集,但不要混入dev/test集合中,这样一来,web/手机场景下的猫的照片中的公共特征,会在训练过程中提取出来,并且我们的训练结果,也是针对手机场景进行优化的。
调参的基本模式
这里的调参主要指的是确定Hyper-parameter最佳取值的过程。所谓Hyper-parameter,即类似DNN的层数、各层神经元的个数,以及其他一些影响神经网络拓扑结构和优化程度的众多参数。在许多DNN的应用算法中,这些参数的取值,对最终模型的执行效果有明显的影响,因此需要予以特别关注。
在真实的应用场景中,可以采用两种方式对应用进行调参:
- Panda模式: 顾名思义,即像照顾熊猫那样的来进行参数的调整。这种调参方法一般就是时刻监控线上的各项指标,然后由训练过的人员,通过指标观测结果,对线上的某些参数进行微调,以确保真实应用表现处于较高的质量水平。
- Caviar模式: 即类似鱼类的繁殖过程,产下大量的卵,利用竞争机制、适者生存。具体来说,可以理解为进行多组并发实验,尽可能尝试各种Hyper-parameter的取值组合,而后选取其中表现最好的那组,上到线上。
需要注意的是,在某个时期选定的Hyper-parameter,在经过一段时间以后,由于所处的应用环境变化(如人群、数据偏好变化),可能就不是最优的了。因此,往往需要持续进行监测,或者定期进行参数的review,以确保DNN一直处于较好的运转水平。这在现实应用中,是一个需要考虑的工作量1,也最容易被人忽视。
那么,一个应用应当选择那种模式进行调参呢?其实很难说什么方式最好,需要根据自身的实际情况选择。比如,你有多少线下训练资源?如果资源充足,那么Caviar模式就比较合适。还有诸如参数衰败的速率(一组调好的参数,能够支撑多久)、不佳的参数对应用的影响程度等,都可能影响你的决策过程。
进行Error分析
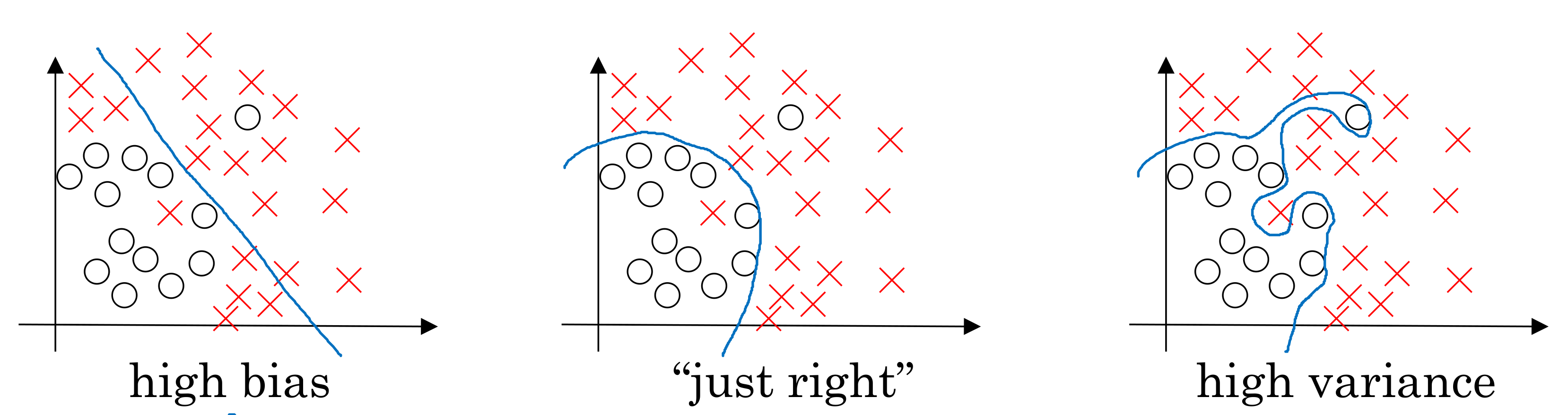
一般我们看一个训练好的模型的性能表现,一方面要看是否能够将样本集合中的数据,计算得到正确的结果;另一方面,又需要具备一定的泛化能力,在面对样本中没有出现过的数据的时候,也能够表现良好。我们一般将前者表现不佳的模型称为High bias或者under-fitting,而将后者表现不佳的称为High variance或者over-fitting。这两个结果往往是矛盾的,比如在train集合表现良好的模型,可能只是简单的”记”住了样本的信息,而不具备泛化表达的能力。在现实中,我们需要在二者之间找到一个好的平衡点。
我们进行error分析的过程,其实很大程度就是在判断,当前的模型,究竟是High Bias还是Variance了?而后据此判断下一步调整的方向。具体应该怎么操作呢?我们可以先计算以下这几个值:
- Human-level error(\(E_{human}\)): 一个或者一组专家,所能得到的最好表现值;
- Traing-set error(\(E_{train}\)): 训练集的准确度
- Dev-set error(\(E_{dev}\)): Dev集的准确度
在训练阶段,我们的最终目标是让\(e = E_{dev} - E_{human}\)最小,并且可以简单直观的认为\(e = (E_{train} - E_{human}) + (E_{dev} - E_{train})\),即分解成两段。当\(E_{train} - E_{human} > E_{dev} - E{train}\)的时候,我们认为当前的DNN训练结果准确率不足是主导因素,即High bias/Under-fitting了;而当\(E_{train} - E_{human} < E_{dev} - E{train}\)的时候,泛化能力不足是主导因素,是High Variance/Over-fitting了。
可行的调整方向
如果一个模型的训练被判定为High Bias,说明这个模型的表达能力不足以表达目标问题,因此可以考虑如下几种调整方式:
- 构建更大拓扑的DNN模型,比如使用更多的Layer或者增加Layer中的神经元的数量
- 训练更长的时间,或者采用更好的优化手段,降低\(E_{train}\)的值。如采用momentm, RMSprop, Adam等
- 尝试更多的Hyper-parameter调优,以降低\(E_{train}\)的数值
反之,如果一个模型被判定为High Variance,那么说明这个模型的泛化能力不足,因此可以考虑进行如下调整:
- 使用更多的数据进行训练
- 选用Regularization方法,如Dropout等
- 测试不同的Hyper-parameter,降低\(E_{dev}\)的数值
策略研发人员在日常工作中,经常要经历若干次这样的error分析,反复调整以得到最佳的模型。采用科学的方法进行分析,是能否快速得到一个表现良好模型的关键,也是衡量一个策略研发人员经验能力的重要参考。
-
目前有一些自动调参的算法,后续有时间可以调研介绍 ↩
About Me
