经典分布式论文阅读之GFS
GFS1发表于SOSP’03,与前面发布的MapReduce一道,是当时Google为了应对自身业务海量数据处理需求而研发的系统。在GFS之前,也存在不少NAS(Network Attached Storage)形态的分布式文件系统,那么GFS的不同体现在哪些方面呢?
最关键的在于,GFS是针对大数据处理场景作出的设计,具体来说包括以下几点:
- 需要能够运行在经常故障的物理机环境上。只有做到这点,这个系统才能运行在几百到上千台规模下,并采用相对便宜的服务器硬件;
- 大文件居多2。存储在GFS上的文件的不少都在几个GB这样的级别,这与之前大家概念中的文件大小普遍在几K的场景很不一样;
- 大多数写是append写,即在文件末尾追加3。这与常规文件系统需要做许多随机写的场景很不一样;
- 可以要求上层系统(如MR)做一定的适配,牺牲一些通用性
- 全系统可以提供的数据吞吐带宽,是比访问延时更加重要的指标;这会对GFS系统在数据分布、网络拓扑感知等方面,提出一定的设计要求。
GFS文件中提到的这些大数据时代对存储系统要求的基本洞见,极大的简化了GFS的设计、使得其在大数据场景下能够最大限度的发挥一个基础存储系统的价值。这些基本特征,在今天看来仍旧适用。Google在大数据时代的早期,就能够如此准确的把握住这些,不得不令人佩服。
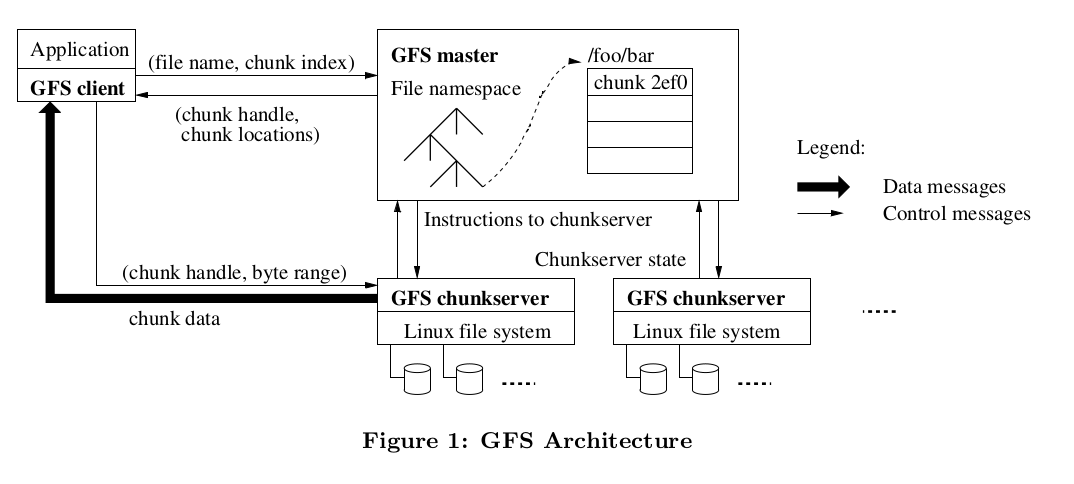
整体结构上,GFS由单一的Master节点、ChunkServer和提供给用户的client三大部分组成。所有的数据,被切分成固定大小的”chunk”,写入ChunkServer所在的物理机的磁盘上,由chunkserver负责管理。而master节点一方面负责管理好所有的元信息,包括表示文件系统目录结构的namespace、文件所属的chunk所在位置等,另一方面负责一些管理行为,比如chunk的负载均衡、垃圾回收(GC)、chunkserver探活等等。用户需要读写文件的时候,通过GFS的client,首先从master查到文件所在的chunk相关信息,而后直接与对应的chunkserver通讯。这么做是为了将大量的访问读写请求,打散到众多的chunkserver上、避免将master节点压垮。
GFS采用单一master的设计,规避了许多分布式方面的问题4,但同时也影响了全系统Scale-out的能力。在Google提出GFS的那个时代,这个问题不算严重。Google通过一些优化手段,确保了单一master可承载的规模满足当时google的应用场景需求。
在GFS的Master设计中,考虑了大量的控制逻辑,比如:
- namespace采用全内存的数据结构,以提高访问的吞吐
- master本身并不记录chunk的位置,而是在启动的时候,通过收取chunkserver的信息来构建。这种设计避免了master和chunkserver的信息不一致的问题(因为以chunkserver为准)
- master和chunkserver通过定期心跳来保持信息同步、感知chunkserver故障等
- master通过往磁盘上写操作日志、并将这些日志sync到其他物理机保存的方式来确保数据安全性。当前master机器故障的时候,可以通过这些日志和chunkserver的心跳内容,恢复到故障前的系统状态
- 对于操作日志,会定期在系统后台执行checkpoint;checkpoint构建成一个类似B+树、可以快速的load到内存中直接使用的结构
- master需要定期检查每个chunk的副本情况,如果副本低于配置值,就需要将通知chunkserver进行复制;如果存在一些多余的chunk(file已经被删除了),就需要做一些清理工作
而在chunkserver端,则采用了以下几个重要的设计机制:
- 每个chunk会被复制多份(典型场景是3份),放到多台打散的物理机上(一般要跨rack)
- 通过租约(lease)定义主chunk副本、负责接受写入操作;租约由master负责分配,确保唯一性
- 采用链式传播5而非扇形传播6的形式分发chunk变更,以便将网络的压力分散到众多物理机上,避免单一机器的网络被打满
- 通过checksum保证数据的完整性,避免磁盘损毁后返回错误的数据。chunk内每64kb将生成一个32bit的checksum,当client读取数据的时候进行纠对,通过后才返回给client
以上只是罗列了GFS中的一些比较重要的设计思想,文中其实还有很多细节在这里没有深入展开,因此如果感兴趣,还是建议完整阅读一下全文。之后20年的许多存储系统,还能看到GFS的影子,有很强的借鉴和学习价值。
-
本文是MIT-6.824课程的阅读作业 ↩
-
这个假设在AI训练场景存在一些变化。在AI训练场景下,往往有大量的小文件(如图片),需要作为训练数据输入 ↩
-
线上日志append追加写;MR也以append写的模式进行IO操作 ↩
-
单一master的结构,其实限制了namespace的大小,也就是一个集群可以存储的文件、chunk的规模。如果将这些数据以某种规则shard分开,又可能引入分布式事务方面的问题,比如前面mr论文中要求rename动作具备原子性,在shard后的master中就需要做一些特殊处理 ↩
-
多个副本组成连表形态,每个副本接收到写入信息后,将写入信息传递给下一个 ↩
-
主副本接收到写入信息后,广播给其他从副本写入 ↩
About Me
