经典MapReduce论文阅读记录
前一阶段将主要的学习精力放在了深度学习上,过了一遍Coursera上的deeplearning.ai系列课程,对DNN的基本概念有了一定的了解。近期会将技术学习的重心回归到我的本行分布式系统上。从某种程度上来说,技术热点什么的,随着行业的发展会不停的变化;但一些基础性的东西,却能够长期的存在下去,因此有必要每隔一段时间做一些基本功的夯实动作,结合当前时代特点,沉淀历史知识中最精华的部分。
近期准备开始追踪MIT-6.824这门课程的内容,扫了一眼课程目录,感觉相当不错。整个课程的设计里面,大概有\(\frac{2}{3}\)的内容在以前零零碎碎的阅读过,但基本是在自己入行初期阅读的,初读的时候比较懵懂,在多年以后的今天重新温习,估计会产生新的体验;剩下的\(\frac{1}{3}\),虽有所耳闻,但一直没有安排阅读,因此跟着课程阅读正好。另外,课程里面的几个Lab都挺有意思的,尤其是raft的协议实现,是心理一直心心念想尝试实现一下的的。因此,follow这门课程的正好可以达到自己“温故而知新”的目的。
By the way, 看这门课程,MIT不愧是MIT,课程压力其实蛮大的;作为阅读过这里过半文献的人,看到这个课程表的时候,都有满满的压力,对于那些初入分布式领域的学生来说,这个压力应该更大。但课程内容是极好的,如果学生真的能够学下来,相当于以几倍速进入领域,也难怪MIT学生会如此受到大企业的欢迎。
按照课程的要求,每篇文献阅读以后,需要写一篇短文作为记录。因此,此文是第一篇文献的阅读笔记,也就是开创了大数据时代的经典文献之一,Apache Hadoop的思想源头:MapReduce。
MR诞生的背景
Google研发MR的时候,整个互联网刚刚兴起,有海量的数据需要处理,典型的如搜索建库、机器学习、统计分析等。因此,许多研究人员都在看如何能方便的实现对海量数据的处理,提出了不少的研发框架。这类系统一般立足于解决如下几个问题:
- 一套方便易用的编程接口
- 并行化计算,缩短海量的、分布于众多磁盘上的数据的处理时间
- 处理分布式场景下的系统容灾问题(网络、磁盘、单机故障)
MR就是这个时期由Jeff Dean提出的Google的解决方案,后来Yahoo的工程师们根据MapReduce和GFS的思想,做出了Hadoop系统(包括MR和GFS),成就了第一代大数据处理的基础设施。
基本编程模型
在编程模型上,MR的思想来自于LISP,其计算的基本过程如下:
- Map: 对于每一条输入的record,计算得到一条或者多条形如 <key, value> 的中间处理结果
- Reduce:将相同key的value收集起来,以 <key, [value1, value2, …]>的形态送入用户程的reduce程序,让用户基于此计算得到新的record
用户通过编写Map和Reduce函数,注册到框架内。框架将需要Map/Reduce计算的数据准备妥当后调用,执行结果写回分布式文件系统中。整个过程,用户无需感知其他复杂的诸如分布式系统、task和数据调度之类的内容。
实现要点
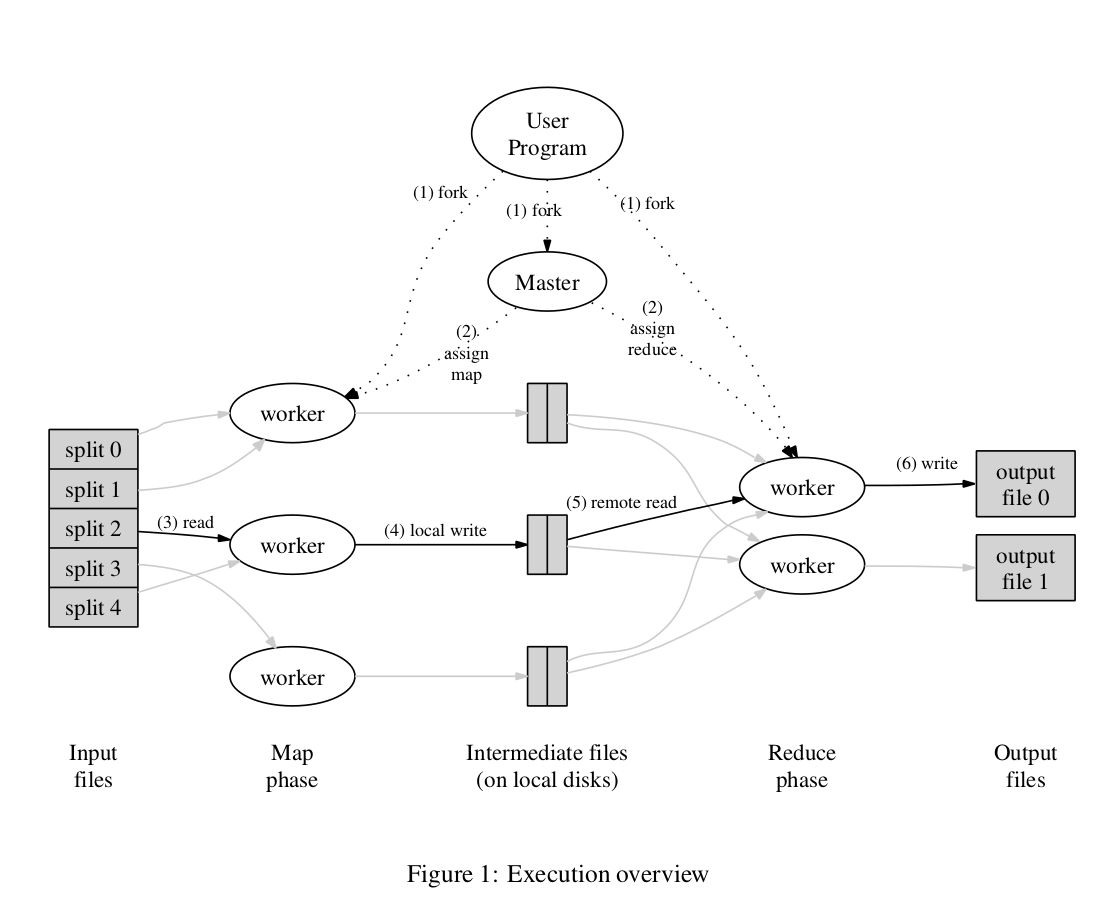
如上图所示,用户的MR程序,在运行时会fork出一个唯一的Master,以及众多用于执行map及reduce的worker进程,并分散到多台物理机上执行。其中,Master负责记录每个切分后的任务的状态(idle、in-process、completed),Worker负责从master领取分配给自己的任务执行具体计算。
每次运行的时候,会启动M个用于执行的Worker和R个用于执行Reduce的worker。map和reduce所需要的数据所在地的信息,都经由master中转。比如上游map产出的抓取地址、上游map任务的执行进度等,这些基本信息都在master有记录。所有的map、reduce的协调工作,由master负责。这种结构显著简化了系统的设计,避免了worker之间的各种通讯和协同问题。
用户的map/reduce程序,一般需要是确定性的,即相同的输入,不论何时执行、执行几次,都应该返回相同的结果。在这个假设条件下,如果一个worker中途执行失败,Master感知后可以把相应的任务assign给另一个任务执行。对于map任务来说,如果因为网络隔离的问题导致有多个map执行了相同的计算任务,那么master会接受第一个计算结果;对于reduce来说,如果有多个reduce执行,则由于reduce的output需要写回分布式存储系统,于是采用每个reduce写入自己的目录,在成功后通过rename动作将对应结果从临时位置移动到真正的output位置1,那么就能够确保只有一个reduce结果可以被下游看到2。对于Master挂掉的场景,由于Master只有一个节点,其存在执行失败的概率较低,因此最简单的做法就是在client端重做整个作业;在MR这篇论文提出的时候,Google并没有对此作太多的处理3。
优化考虑
在基本的实现之上,文章中还提到了一些优化手段,这里简单罗列如下:
- 数据的局部性: MR框架会通过查询分布式文件系统(DFS),尽可能的将task调度到数据所的物理机、或者接近的网段上;这个能够有效减少需要传输的数据量。
- 任务的粒度: 一般而言,需要让M和R远远大于worker机器的数量,即让任务粒度足够小。这样一来可以实现更好的负载均衡。性能强的机器处理更多的task、性能差的处理得少一些;二来task重做的时候,发生重做的部分会更少些。经验上,最好将任务分割成处理64MB/128MB粒度的task为佳4。
- Backup-task: 在现实中,可能出现一些任务执行不正常(比如调度到故障机器)上,执行极慢导致整个job都在等待这几个任务结束。因此解决的手段是对于一些任务(一般选择最后调度上去的那批、或者执行时间超出大多数其他任务平均时长许多的),重复的提交一个,然后master先收取第一个执行完成的结果。这能够有效的消除长尾问题。
- 分区hash可定制: MR框架提供了可定制的分区计算方法,使得业务可以根据需要,引入自身场景以方便编写任务。比如在建库的时候,可以以hostname来作为hash的key,让同hostname的网页都落入同一个reduce进行处理。
- 顺序保证: 在框架中,确保了每个分区内部,都是按照key的顺序进行处理的,这样就给全局排序这样的任务提供了实现的基础。
- Combiner: 在许多场景下(比如WordCount),可以在map端作一轮的合并,然后让reduce在map已经合并过的基础上进一步合并结果。因此,引入了Map端的Combiner的概念,以显著减少map-reduce之间需要走网络传输的数据量。
- 信息披露: 为方便用户,MR框架可以查看所有task的执行状态,并提供了Counter功能进行一些用户层面的统计计数。这样用户就能够从这些基础信息中,了解自己任务的执行情况,在外围做一些诸如监控、管理类的行为。
从上面的优化手段可以看出,用于大数据处理的系统,其基本优化方向在于减少磁盘或者网络的IO,这与后来兴起的AI训练场景的优化方向有很大的不同,此为后话。
总结
MR的设计思想非常简单易懂,且文献中提到的许多内容对后面许多系统的设计都有影响。在现在看来这些思路都是很基础的。在2000年前后,分布式系统、大数据还处于萌芽状态的时候,这么多重要的基本思路出现在同一个系统的设计中,还是非常牛逼的。MR无愧于大数据时代计算引擎的开山鼻祖。Jeff Dean因此一战封神。
About Me
