Google的Borg论文都说了啥?
一直以来,Google大名鼎鼎的Borg没有对业界公开其资料,大家只能从各种渠道拼凑出系统大致的模样。在EuroSys’15上,Google终于发表了介绍Borg的论文,揭开了它神秘的面纱。为了缩短大家的阅读时间,整理了这篇文章,阐述下论文披露出来的一些关键设计思想,并结合自己的理解进行一些探讨。
Borg定位于解决什么问题?
与绝大多数集群操作系统(Cluster Operating System)一样,Borg立足于解决以下三方面的问题:
屏蔽底层基础设施,使得产品线专注于自身需求
当系统规模大到一定程度,许多基础设施的升级,比如更换系统内核/基础库环境(glibc, kernel等)、底层网络建设等,都不可避免的会被上层业务感知、需要逐个推动业务线的升级调整,实施非常困难。而从业务线来说,这些升级和自身的主营业务并不相干,却需要进行配合而产生不小的人力开销,是一件没有业务收益、低优的事情。这种矛盾进一步使得基础设施的演化推进变得更加艰难。时间一久,基础设施建设将会远远落后于业内的最新进展。
Borg类系统的出现,解耦了基础设施和上层业务。业务可以近似无成本的享受到诸如内核、网络建设等底层系统调优升级带来的好处,将精力更多的聚焦于自身业务。而对于基础设施的人员来说,则减少了各种推动性工作带来的大量人力开销。
以内核的升级为例,Google要求业务都具备一定比例的宕机容灾能力,IDC会按照规划、强制按照一定比例随机shutdown机器进行维护。在这种机制下,全公司可以持续更新至使用业界最新版本的内核、更新操作系统环境。且由于经常重启、遇到内核问题的概率也随之下降了许多。强制重启机器的机制,不仅可以消除五花八门的机器环境问题,也倒逼这上层系统按照分布式系统的方式进行系统架构设计,提高了业务的可靠性。
提供稳定可靠的API,方便产品线方便运维
borg的API、尤其是Borgcfg工具的出现,使得任何一个人都可以方便的部署、运维自己的服务。Google的MapReduce、Flume、Pregel,甚至大名鼎鼎的GFS、Bigtable等著名分布式系统,都是基于Borg的API、托管在Borg系统之上的。这种分层结构,大大简化了上层系统在运维方面的设计。
此外,borg提供的borgcfg是Google内部员工日常使用的重要工具之一。该工具可以方便的执行诸如线下的各种测试及调研任务、甚至直接操作线上服务。borgcfg描述支持继承和导入,这种描述能力使得用户可以最大程度的复用历史积攒的经验,将搭建环境的行为自动化起来。
管理好物理资源,提高资源利用率
通过Borg系统托管的业务,具体进程启动在那台机器上,是由调度算法决定的。于是,Borg可以根据当前集群负载和被调度业务的资源需求,通过充分的隔离、超发、自动扩缩容等技术,进行混布以提升物理资源的使用率。和业务线自己进行手工混布的方式不同,这类工作是由独立、专业的研究团队通过数据分析等方式反复进行迭代优化的。此外,相对于业务线零碎机器池,由于Borg掌管了全公司的物理机器,使得调度算法具备全局资源视图,能够充分调配并做出全局更优的选择。
负载的类别:service与batch job
运行于Borg系统之上的应用(“进程”)大体有两类,一类被称为”service”,启动后即长时间运行不断接受并处理收到的请求,类似daemon进程。一般而言,service对请求处理延迟和可用性比较敏感、多数服务于终端用户(如Gmail、Google Docs等)。第二类应用被称为batch job,这类程序执行结束后自行退出,往往执行时间短、对执行失败不那么敏感。典型的batch job为各色的离线计算任务。
那么,为什么需要区分两种不同的负载呢?原因是这两类负载的差异性实在太大,需要用不同的思路去处理,具体包括:
- 二者的运行状态机不同::service的状态机中,是存在『环境准备ok,但进程没有启动』、『健康检查失败』等状态,这些状态离线作业是没有的。状态机的不同,决定了对这些应用有着不同的『操作接口』(对应状态机中的『边』),进一步影响了用户的API设计(比如离线作业没有『更换程序重启』、而是『提交重做』)、上层控制系统的内部实现(控制系统需要通过一致的『操作接口』来控制所有『进程』的运行状态)。
- 关注点与优化方向不一样:一般而言,service关注的是服务的『可用性』,而batch job关注的是系统的整体吞吐。关注点的不同,会进一步导致内部实现的彻底分化。比如,对于服务来说,其调度更多的关注于Failure Domain的处理,而离线作业更多的是通过DAG等信息优化任务的启动顺序、确保系统的整体吞吐等。
基本架构:borgmaster/borglet/scheduler
Borg是非常典型的Master(borgmaster)+Agent(borglet)架构。用户的操作请求提交给Master,由Master负责记录下『某某实例运行在某某机器上』这类元信息,然后Agent通过与Master通讯得知分配给自己的任务、在单机上执行管理操作。
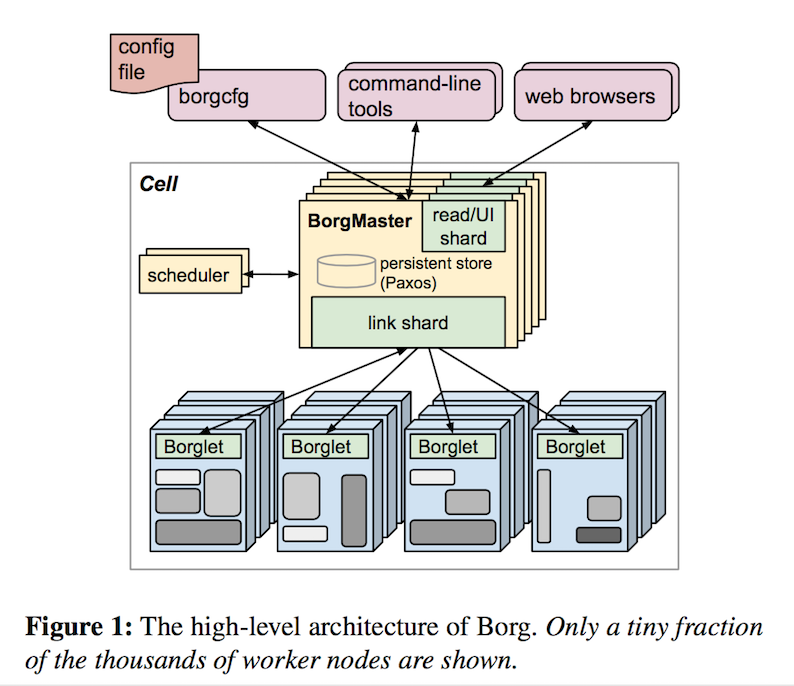
每套borg部署称为一个cell。在Google的机房环境下,IDC和cell是1:n的关系,一般而言是一个主Cell运行着大多数的业务,和若干个特殊用途的小cell。每个cell有一组borgmaster进程,以及部署在众多机器上的borglet(一台机器一个)进程组成,管理的机器规模一般在万级别。
每组borgmaster由5台机器组成,使用paxos协议进行选主和元数据的同步、消除系统单点。所有的写操作由选举出来的leader执行。borgmaster定期通过rpc向borglet查询状态、下发分配的任务等等。当系统机器规模很大的时候,过多的agent通讯和查询需求可能导致leader负载过重。因此,borg将轮询工作分摊到各个follower上,只有borglet汇报的状态发生变化的时候,才将变化通知给leader处理;此外,对于数据没有强一致需求的查询请求,也由follower处理。
在早期的borg设计中,调度器是实现在borgmaster中的,如今borg已经将调度器拆分成独立的服务(融入了omega的设计),一方面降低了master的压力、另一方面也利于调度策略的独立迭代。论文没有披露太多关于调度器的实现细节,讲了一些常见考虑要点、show了一些图表表明集群调度的好处以及调度算法评估的一些初步知识(论文嘛,总得有些图和数据show一下,你懂的)。
在论文中,borg还有一些重要的功能,比如内置了名服务用于服务发现、公司级别的rpc框架内置http server以方便获取监控信息、带web ui的sigma系统用于日常稳定定位追查、fauxmaster负责进行线上负载的仿真以支持调度算法优化和borg自身的debug等。
为提升资源利用率,borg做了哪些工作?
从论文披露的信息上来看,Google为支持混布,做了许多精细的工作,具体包括:
cgroups进行物理资源隔离
事实上,当前linux kernel中用于物理资源隔离的cgroups,就是google borg研发团队贡献给社区的。这个工作是后面众多容器技术的基础。早期的lxc,以及后面发展起来的docker等,都受益于google的贡献。
优先级、超发与抢占
在borg系统上运行的程序,都需要指定具体的优先级。优先级是一个数值,但会从高到低分成四个大的区间(priority-band):monitoring, production, batch, best-effort。从名字上就可以看出,分别对应:基础服务、在线业务、离线计算,还有一个特殊的best-effort。业务预算时需要指明自己需要购买的资源优先级。在业务提交请求的时候,borg会检查当前对应优先级下是否还有配额可用。不同级别优先级的资源有不同的价格,影响到具体业务部门的最后财务报表中。
在borg上运行的程序,一般原则是,高优先级可以抢占低优先级,但production及monitoring通常不会被抢占。在整机资源不足的时候,borglet会按照优先级数值的倒序(这时候不管处于哪个priority band了)逐个kill,避免机器被打死。当borgmater感知道一个任务被evict了,就会将这个任务重新调度到另一台机器上去执行。
在系统运行的过程中会发现,用户往往会多申请一些资源,以确保程序压力突然上升时能有一定的冗余空间(required > used)。如果在分配资源的时候,简单的以用户的请求值来分配,那么机器上就会累积大量的闲置资源。为此,borg提出了reclaimed-resource的概念解决这个问题。
简单通过例子来说,一台机器有100大小的物理资源,这时候先以monitor/production优先级申请了60,但是实际只使用了40,那么机器就出现了(60-40)=20的闲置资源(reclaimed-resource)。borg的处理思路是,当来了一个batch/best-effort优先级的资源需求的时候,那么就认为这台机器总共有100+20=120、还剩120-60=60的可分配资源,而对于monitor/production优先级的请求来说,则认为机器还有100-60=40的可分配。
这种分配方式,确保了在单机上分配给monitor/production级别任务的资源之和,不会超过真实物理资源。当monitor/production级别的资源使用增长到其申请的配额数的时候(比如流量增长导致资源使用从40变成了60),可以通过抢占低优先级任务来满足其需求。
borg通过这种机制实现了机器资源的超发,大大提高了资源利用率。从一些小道消息了解到,Google的机器利用率长期处于高位,极大的节约了公司运营成本。
通过CPI进行混布干扰的评估
尽管目前隔离技术已经做得比较完善了,但将多个进程在一台机器上运行,还是可能引发一些性能上的overhead。borg团队为此做了一些研究,最后选择了使用CPI指标来进行度量、并基于这个指标进行了一些优化工作。CPI是Cycles Per Instruction的缩写,CPI上升则意味着程序性能下降,是一个无关于具体应用、可以被硬件采集的通用指标。borg通过采集CPI数据,可以对比一个应用混布与非混布相对的性能损耗,以及不同应用混布所带来的干扰大小(用于调度算法),并结合优先级、CPU利用率等信息,从众多的进程中识别出干扰源并kill。这部分工作google有另外一篇单独的论文介绍(CPI2 : CPU performance isolation for shared compute clusters),感兴趣的人可以展开阅读。
修改内核调度算法以减少对延时敏感应用的影响
有些应用对延时非常的敏感,比如大搜索等直接服务于用户的业务。对于延时敏感的业务,borg支持在提交资源的时候,打上LS(Latency-Sensitive)标记。borglet看到有LS标记的时候,会确保LS与LS应用不会共享物理cpu核发生干扰。但,none-LS应用可以与LS应用共享物理cpu核,而后通过修改内核调度算法,确保LS在调度的时候比none-LS获得更多的cpu时间片,从而减少none-LS与LS共享物理cpu核带来的影响。
结语:Borg引发的思考
在阅读完borg论文之后,个人最大的感触在于Google的基础设施建设上的强大的前瞻能力、并且能够投入十多年进行不断的优化和改进。正是Google在基础架构建设方面的前瞻性和精益求精的精神,奠定了它在技术领域的领先定位和在业务上彪悍的创新能力。
About Me
