Firmament调度算法一(模型介绍)
今天开始阅读一篇OSDI’16上发表的论文,全名为《Firmament: Fast, Centralized Cluster Scheduling at Scale》,比较新。和前面DRF一样,也是一片非常经典的论文,因此也准备采用多篇blog的方式,进行分解精读。论文中提到的MCMF,是对调度问题的非常好的建模,在这篇论文分解阅读完成以后,很有必要对类似算法进行一个比较细致的梳理和比较。
在开始展开介绍Firmament算法之前,论文先阐述了一些作者对调度算法的理解,可以从以下两个纬度对集群调度算法进行”分类”:
- 按架构划分
- 中心化(centrilized):中心化的思想是整个集群的所有任务的调度,都由同一个调度器来做,即这个调度器掌控着集群完整的资源视图和对任务的调度权力。中心化调度器的最大好处在于可以全局统筹,能够实现较高的调度质量,减少资源碎片。但中心化的缺点也比较明显,当集群规模或者任务量巨大的时候,中心化调度器的性能就会是一个很大的问题。比如用户响应会比较慢、资源空闲可能会空闲着等待调度器分配给自己新任务。
- 分布式(distributed):分布式化调度器和中心化调度器是相对的,也即在一个集群上,存在多个调度器,每个调度器有自己的资源视图,并根据这个资源视图调度自己负责的那一部分任务。由于资源视图和任务量都被分拆了,分布式化调度器一般性能表现较中心化的好。但由于涉及到资源视图的信息同步问题(调度器A commit了一个任务,但调度器B不知道),就可能出现调度结果冲突;分布式调度器的结果一般难以做到全局最优。
- 混合型(hybrid):Hybrid型是一个折衷方案,是中心化和分布式化的混合。比如,对于long-running的service,采用中心化的调度方法;而对于生命周期较短的batch job,采用分布式的算法。long-running的调度,由于service迁移的成本比较高、调度需求量较小,因此采用比较重的中心化调度算法是很合适的,而生命周期较短的batch job,对于调度时间要求较高、且结果不优的影响较小,因此可以使用分布式调度器。当然还有其他的混合方式,论文里并没有细说。
- 按调度行为划分
- Queue-based:Queue-based调度比较好理解,调度器维护一个队列(queue),用户提交的job调度请求先放到这个队列里面,而后调度器定期的从队列中取出某个job/task,寻找资源将这个job/task启动起来。对于一些繁忙的集群,可能除了调度器上需要有个job的pending queue之外,在worker上也可能增加一个worker queue,以控制task在单机上的启停。queue-based的调度算法非常直观,并且非常适合分布式调度器。但其一次处理一个job/task的模式,使得调度器并未考虑排在后面job/task的情况,无法做出全局最优的调度。
- Flow-based:Flow-based的调度算法,其基本思路是批量的处理好众多job/task之间的关系,以一个有向无环图(flow)的形式将众多任务”放置”到图中组织起来,然后在这张图上执行图算法得到基于当前信息的最优解。典型的Flow-based算法包括Quincy,以及这篇论文提到的Firmament算法。Quincy也是一个非常经典的算法,它阐述了如何构建Flow,并在Flow上通过执行MCMF(Min-cost Max-Flow)算法以得到最优调度结果。但Quincy的计算量太大、响应很慢(分钟级)。因此又有了Firmament算法,对Quincy算法进行了改进,一方面达到和Quincy一样的调度质量,另一方面又缩短了调度执行时间(百毫秒级)。
那么,一个调度问题是如何建成一个Flow的呢?以下图为例:
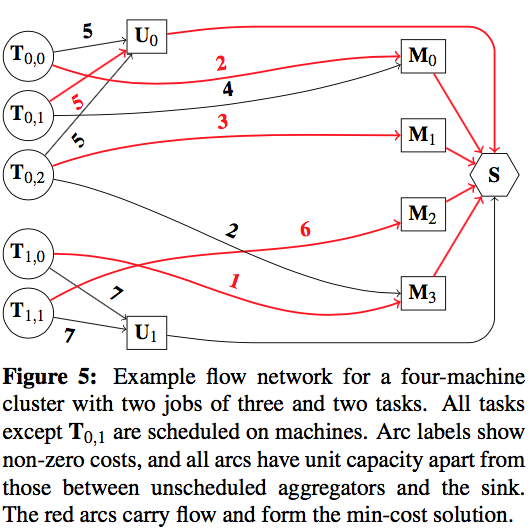
图中的\(T_{i,j}\)表示Job-i的第j个task,而\(M_{h}\)表示物理资源(机器),还有一类特殊的节点用来表达一些”策略”(论文中称为aggregator node)。比如上图中的\(U_{i}\)节点,如果一个\(T_{i,j}\)连接到\(U_{i}\)上,则表示\(T_{i,j}\)这个task被塞到pending队列里面不执行。图中的边表示做出一个选择所需要付出的”代价”(cost)。比如图中的\(T_{0,2}\),如果不启动,其付出的代价为5(指向\(U_{0}\)的边),而如果调度到\(M_{1}\),则需要付出的代价为3(指向\(M_{1}\))。
图中的\(S\)被称为Sink node,从\(T_{i,j}\)出发,最终都会指到这个\(S\)节点上。而整个调度算法的”最优解”,则表达为对每个\(T_{i,j}\)选择一条通向\(S\)路径,使得整个图的”cost”之和最小(MCMF: Min-Cost Max-Flow)。比如上图中的红线就是解,即将\(T_{0,0}\)调度到\(M_{0}\),\(T_{0,1}\) pending等待等等。
这个模型的威力在什么地方呢?在于我们可以通过设计合适的aggregator node和权重计算的方式,在一个框架下丰富调度策略。
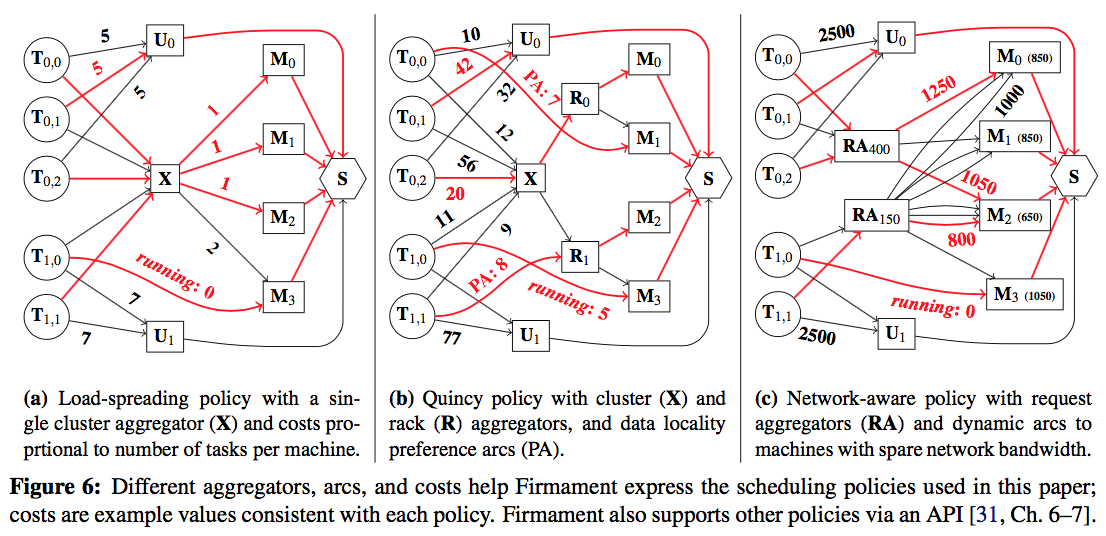
比如,在Firmament论文中提到以下三个:
- Load spreading policy: 具体做法为增加一个”X”的节点。所有的\(T_{i,j}\)都有一条指向\(X\)的边,且\(X\)和所有的\(M_{h}\)相连,其权重体现了机器当前的负载情况。比如a图中,\(T_{1,0}\)正在\(M_{3}\)上运行,\(X \to M_{3}\)的权重就高于\(X\)到其他的边。执行MCMF算法后,就能达到”负载均衡”的效果。
- Quincy policy: 这个策略非常实用,即需尽量将将task调度到数据所在的地方。图中的\(R_{r}\)表示一个机架(Rack),如果\(T_{i,j}\)所需的任务,其需要的数据放置在某个机器上,则以较小”cost”连接对应Task和M(或R),如图b中的\(T_{0,0} \to M_{1}\)和\(T_{1,1} \to R_{1}\)。而\(T_{i,j} \to X\)则表示不考虑数据局部性的cost估算值。执行MCMF算法后,算法的结果则揉入了对数据局部性的综合考虑。这个策略在现实中,对离线计算非常有用。将任务调度到离数据”近”的位置,能够显著缩短任务执行时间、降低集群的网络压力。
- Network-aware policy: 这个策略主要说明如何避免一个资源被超发(以网络带宽为例)。基本思路为引入\(RA_{x}\)的node,表示某个task需要申请x的资源量,如\(RA_{400}\)表示连接过来的任务需要400MB的网络带宽,然后与所有申请这个资源量的task相连。如果某台机器足够支持某个资源的申请量,则在\(RA\)节点和这台机器的节点建立一条边,其权重为机器上的闲置资源量,加上申请资源量(图中\(1250 = 850 + 400\),边\(RA_{400} \to M_{3}\)因为\((1050+400)>1.25GB/s\)万兆网流量而不存在)。
从上面的几个例子可以看出,基于MCMF,可以将这些策略”叠在一起”,非常漂亮的表达出各种调度策略。一个典型的Flow-based调度算法,其权重值是随时根据当前现状计算得到的,即算法总是基于现状信息而得到的一个”最优解”。
另外,在现实的集群中,一个集群往往有几万个节点,以及揉入各种策略而引入的众多”策略节点”和边,导致MCMF计算量巨大。因此需要进行一定的改进,以降低调度算法的执行时间。这些内容会在后面的论文解读中予以介绍。
About Me
