Quincy调度算法一(背景篇)
这个周末抱着新到货的Sony DPT-RP1跑到国家图书馆装逼,阅读的主要内容就是SOSP’09发表的Quincy论文(《Quincy: Fair Scheduling for Distributed Computing Clusters》)。论文发表的时间比较早,非常经典,其主要贡献在于将全局资源调度问题,以图的形式(Flow-based)表达并用标准的图算法求解;且后续的策略调整,可以通过引入额外的”策略节点”和调整边及权重的方式来施行,非常易于迭代。在论文中,作者用这个模型,给出了一个将计算任务”最优地”调度到数据所在地的有效算法,具有非常高的实践价值。论文的铺垫部分比较长,一方面可以当做经典Queue-based调度算法的Survey,另一方面又能作为Flow-based类型算法学习的起点1。
回到论文里来,Quincy试图解决的问题是什么呢?其实很好理解,在进行作业调度的时候,我们需要考虑被计算数据的分布,将计算作业尽可能的调度到数据所在处(三个层次:机器computer、机架rack、机房cluster)。如果计算作业和数据分离太严重,那么计算的时候,就需要通过网络远程读取(or写出)数据,导致网络带宽出现瓶颈、降低集群的整体作业吞吐。另外,网络通讯每穿透一级交换机(机架->机房->地域)都要受制于”收敛比”,这就使得问题愈加严重。
论文的铺垫部分,介绍了许多背景知识,对理解调度问题很有帮助。因此,这篇blog先详细介绍了这些铺垫内容:
第一个问题,计算作业长啥样?
典型的计算作业是由一个root-task(hadoop中的AppMaster),和一组worker-tasks组成。Worker-tasks一般会构成一个DAG图; root-task负责”管理”这个DAG,决定哪些worker-task可以启动。每次启动job的时候,都是先在集群找一台机器2启动一个root-task,然后root-task再交互式地通知调度系统启动那些处于”ready”状态的worker-task。
但需要注意的是,root-task只是通知调度系统”这些worker-task可以启动了”,实际是否真的启动执行,是由调度系统根据集群资源当前的使用状况来决定的。如果一个task被root-task认为可以启动、但调度器不让他启动,那么这个task就处于pending的状态。一般而言,调度系统会在某些task运行结束、释放出资源以后,按策略选择某些pending任务启动起来。这个选择的策略就是我们常说的task scheduling算法3。
在论文及后面的介绍中,将job-i的root-task记为\(r^{i}\),其第j个worker-task记为\(w^{i}_{j}\)。
第二个问题,作业的数据分布偏好如何表达?
计算作业有输入、也有输出。在大数据场景中,这些数据一般是放置在某个分布式文件系统里面、散落在许多不同的机器上的(如GFS、HDFS)。在计算作业进行调度的时候,root-task可以通过和分布式文件系统交互,查得自己需要的数据放置在哪些机器上,并准备prefer-computer和prefer-rack列表。如果一个机器上放置的数据量超过总计算量的一定比例(or 一定规模),那么就把这台机器加入到prefer-computer列表中。prefer-rack列表也使用类似的策略进行构造。
root-task在和调度器交互的时候,将这两个prefer列表暴露给调度器。调度器会利用这个信息,决定\(w^{i}_{j}\)任务的实际启动位置。
第三个问题,Queue-based调度算法的基本模型长啥样?
简单的说,就是下面这个图这样:
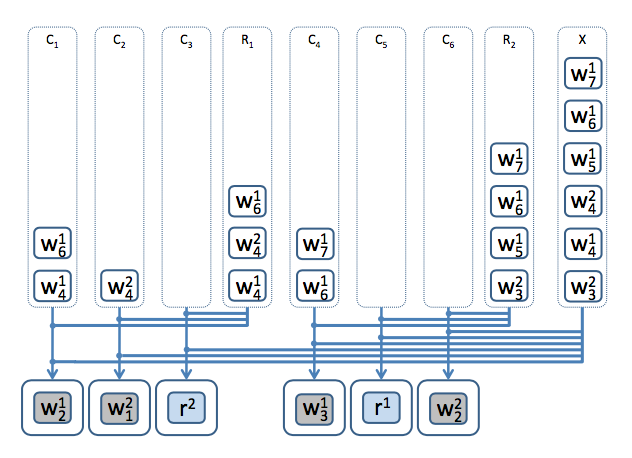
很好理解,在调度器中有三类的”队列”,一类是Computer-queue(图中\(c_{x}\)),每台机器一个,如果机器x在\(w^{i}_{j}\)的prefer-computer列表中,那么\(w^{i}_{j}\)就在\(c_{x}\)队列中。类似的还有Rack-queue(图中\(R_{x}\))和Cluster-queue(图中\(X\)),都是根据root-task反馈的worker-task的prefer队列计算出来的。
这里需要注意的是,一个worker-task,可能被同时放入多个Queue中。比如图中的\(w^{1}_{6}\),其prefer-computer包括1, 4两个节点、prefer-rack包括1、2,那么\(w^{1}_{6}\)就同时出现在\(c_{1}\)、\(c_{4}\)、\(R_{1}\)、\(R_{2}\),当然还有\(X\)队列中。
调度器管理着这些队列,当资源(图中底部的那些框,后称为”槽位”/slot)释放出来的时候,则根据一定的策略,从队列中选取合适的task启动起来。另外,如果来了一个新的job,那么这个job的root-task将会有很高的优先级,可以杀掉某个slot中的worker-task(通常是最近启动的那个倒霉鬼),将这个root-task启动起来。一般而言,对于一个集群来说,需要设置一个参数\(K\),表示这个集群内可以提交的最大job数。由管理员确保设置为\(K\)的集群其Slot数不能低于\(2K\)4。
第四个问题,典型的Queue-based调度算法有哪些?
论文介绍了几个Queue-based的算法,用于和后面的Quincy做对比。包括:
- Baseline without fairness(G): 这个算法最简单直接。每个任务按照其到达的顺序在队列中排队(FIFO)。调度器发现机器x空闲了,则首先选择\(c_{x}\)队首任务启动;如果\(c_{x}\)为空,则选择对应机架的队首任务,以此类推。这个算法的基本思想在于,只要有任务,就需要确保机器处于带负载的状态。但问题也很明显:首先,一个大的作业可能在很多队列中都有它的worker-task在排队,这样一来排在后面的小任务,将很大的概率在队列中停留得过久;另外一个问题在于对于那些无偏好的作业,会被放置在\(X\)中、很难得到调度机会从而被”饿死”。出现这些问题,都是因为G算法没有考虑作业公平性(fairness)方面的问题引起的。
- Simple greedy fairness(GF):这个算法在G算法的基础上,引入作业Blocked的概念。调度器首先计算job-k允许占用的Slot数目(\(A_{k}\)),如果job-k处于running状态的worker-task数超过\(A_{k}\),则将job-k标记为Blocked。处于Blocked状态的job,将不能再启动新的worker-task;直至它运行中的worker-task数目重新回落到低于\(A_{k}\),才离开Blocked状态。GF算法在G的基础上,考虑了公平性的问题,但并不完美。在现实中,新的job加入的时候,需要重新计算所有job的\(A_{j}\)值,一般表现为大家的值都会降低。如果一个作业k的worker-task执行时间很长、且running的worker大于\(A_{k}\),执行中的worker并不会主动退出,这就使得其他、尤其是新加入的job的task一样会启动不起来,”利益”受损。
- Fairness with preemption(GFP): GFP是在GF算法基础上进行的改进,即引入了”抢占”的概念。对于那些超出了自己\(A_{j}\)限额的job,调度器可能会kill掉这个job的某些worker-task,释放资源给其他处于”吃亏”状态的job。一般而言,调度器会选择哪些执行时间比较短的worker-task,以避免一个已经运行很久的任务(有可能就快算完了)被杀掉,减少计算资源的浪费。
- Sticky Slots(GFH/GFPH): 对于一个繁忙、且所有job都基本使用到自己”配额”的集群,就可能出现一种非常诡异的场景:job-k的某个任务在机器m上执行结束了,释放出资源。调度器感知后需要从队列中选择一个新的任务来执行,但此时由于只有job-k的存在可运行的配额(因为刚结束了一个),则只能选择job-k的下一个task在机器m上执行。这样一来,”尽量将计算调度在数据所在地”这一个原则就被抛到九霄云外去了。这个现象有很大的概率会一直持续下去,导致整个集群,大量的worker都没办法被调度到数据所在地,计算作业的吞吐大幅度降低。为解决这个问题,有人提出了一个经验性的改进方法,即让job-k不那么快的从Blocked状态出来,而是”再等等”。比如,让job-k多结束几个任务(GFH),或者多等一段时间(GFPH)。在等待的这个时间内,其他job有可能也有worker-task结束运行,从而打破连锁反应。
读完上面的Queue-based调度算法的介绍,大家有没有一种感觉,那就是Queue-based的算法,有点在”凑”,即不停的在已有算法基础上”打补丁”、解决前面算法出现的问题。至于调度算法是否能够达到”最优”,这些算法都没办法给出一个明确的解答。下一篇blog要介绍的Quincy,将调度问题从Queue-based,建模为Flow-based,使用标准的图论算法来系统性的解决问题。
About Me
