AI系统面临的挑战
近一两年AI技术蓬勃发展,我一直存在不小的困惑,不太清楚AI时代和之前反复提起的大数据时代有何区别、担心时代的发展会颠覆掉之前积攒下来的各种系统知识。今天要介绍的文章(《A Berkeley View of Systems Challenges for AI》),给出了U.C Berkeley RISELab在这方面的思考,一定程度的解读了AI时代的特点、并给出了他们对于AI时代发展趋势的判断。文章属于survey性质,并不涉及高深的专业知识,非常适合入门者阅读。
这篇文章核心话题包括以下三个:
- 促成AI技术如此热门的底层要素
- AI系统的发展趋势和所面临的挑战
- AI在系统层面的潜在研究方向
Topic 1: what is behind AI’s recent success?
文章作者提出了三个基本因素:
- 大量的数据
- 大型可扩展(scalable)的系统的出现
- 便捷地获取最新技术的能力
前两个很好理解,在大数据时代所积攒的大量数据,以及为处理这些数据进而发展出来的众多分布式数据存储、计算系统,是当前AI发展的基础。但如果只是做到了这两点,业内也只会出现类似Google、Amazon这样的大型的互联网公司,无法出现当前如此繁荣的AI生态。AI技术要形成生态,还需要有较高的开放度,使得这些数据、系统能够被巨头之外的企业应用,即实现AI赋能。从文章作者的角度上来看,开源系统和云技术的发展功不可没,前者让众多公司能够快速的搭建属于自己的系统,后者使得他们能够快速的获得弹性的各方面的基础设施资源。
Topic 2: trends and challenges
AI应用的层出迭起,我们需要了解整个行业的基本发展趋势,以便提前研发相关技术以应对其飞速的发展,文中指出了以下四点:
Mission-critical AI
Design AI systems that learn continually by interacting with a dynamic enviroment, while making decisions that are timely, robust and secure.
之前的大数据时代,很多时候我们只是將数据经过某种形式处理后呈现出来(如搜索將结果呈现),然后由人执行具体的决定(如选择点击某个链接)。而AI之所以被称为AI,其中一个很大的差异就在于其可以代替人做一些决定。这个差异隐藏这更加深层次的变化:即系统將开始与真实世界进行交互,需要处理复杂的、持续变化着的现实问题(想想无人驾驶、智能音箱)。如何处理好现实世界的复杂性,是AI系统走向成熟、进入关键应用所需要解决重大课题。
Personalized AI
Design AI systems that enable personalized applications and services yet do not compromise users’ privacy and security.
由于AI系统需要代替人作出决定,那么了解具体的这个”人”的个性化行为就显得十分的重要,需要采集大量的个人的相关信息。如何在不违背用户隐私和数据安全性的基础上,最大限度的利用好这些个性化数据,也是AI系统需要处理好的关键问题。
AI across organizations
Design AI systems that can train on datasets owned by different organizations without compromising their confidentiality, and in the process provide AI capabilities that span the boundaries of potentially competing organization.
AI是一个开放的生态,目前存在一种很有意思的合作竞争模式,即众多的同行业的机构共享自己的数据、然后在全行业累积的数据基础上训练模型,而后从中获利的模式1。在这个商业模式下,行业内的巨头会开始谋求自己成为这个行业数据的”庄家“,收录数据、提供AI服务以抢占市场先机;而那些加入阵营的机构,则会担心自己数据未授权的被自己的竞争对手所盗取、失去自己差异化竞争的能力。如何安全的收集、管理好这些数据,并AI赋能整个行业,是新时代需要解决的重要课题。
AI demands outpacing the Moore’s Law
Develop domain-specific architecture and software systems to address the performance needs of future AI applications in the post-Moore’s Law era, including custom chips for AI workloads, edge-cloud systems to efficiently process data at the edge, and techniques for abstracting and sampling data.
AI技术的发展离不开对大规模数据的处理,但是由于IoE等AI应用场景的高速增长,数据的增长速度高于CPU等硬件设备的发展。这个基本趋势使得我们需要研究针对AI领域特滑的软硬件设备、以及类似边缘计算等新型的云技术,以做好应对的准备。
Topic 3: research opportunities
为应对上述的发展趋势,文章推荐了三个方向下的9个研究专题:
- R1~R3: 应对动态的、复杂的周边环境
- R4~R6: 满足AI的安全需求
- R7~R9: 适应AI的系统架构
这9个研究领域和前面发展趋势的对应关系如下图:
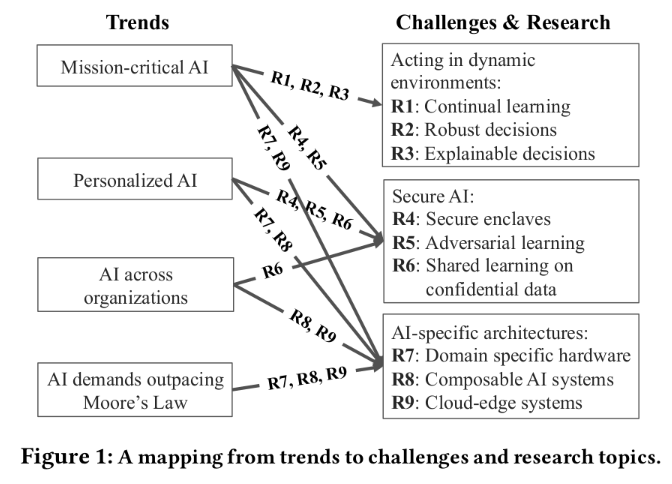
R1: continual learning
- Build systems for RL that fully exploit parallelism, while allowing dynamic task graphs, providing millisecond-level latencies, and running on heterogeneous hardware under stringent deadlines.
- Build systems that can faithfully simulate the real-world environment, as the environment changes continually and unexpectedly, and run faster than real time.
在目前已经发展出来的诸如无人驾驶、机器人和智能音箱的这类应用中,我们可以看到他们都需要持续地和复杂的外部环境交互,并在交互中进行学习。这种模式和之前的”先把数据记录下来,事后训练模型发布的”处理方式很不一样,因此需要研究动态的机器学习方法。
可能会有人想到,这个很像之前经常提到的在线机器学习(online learning)。但在AI场景下这个需求还是很不一样的。核心区别在于online learning还是定位在被动的处理数据、缩短闭环训练时间,而不是试图去做出一个控制决定、也不需要考虑决定之后可能对外部世界发生的影响。
作者提到了一类被称为Reinforcement Learning(RL)的算法,挺适合当前AI场景。这类算法的目标是训练某个处理问题的”策略”(policy),其输入是观察到的某些外部信号,输出是一个行动决策(action)。在执行的时候,算法需要通过仿真各个备选行动可能对外部环境产生的影响后,根据众多的对这些可能的行动的仿真结果,调整自身的”策略集”并选择有利于长远收益的某个决策行为2。RL是比较适应当前AI应用的一类机器学习算法,不仅仅是需要结合具体应用场景找到合适的方式,也需要研发相关系统以适应这类算法的需求3。
R2: robust decisions
- Build fine grained provenance support into AI systems to connect outcome changes(e.g., reward or state) to the data sources that caused these changes, and automatically learn causal, source-specific noise models.
- Design API and language support for developing systems that maintain confidence intervals for decision-making and in particular can flag unforeseen inputs.
健壮性是所有系统都追求的目标,但在AI场景的需求主要来自两方面:
- AI將越来越多的应用在一些关键领域,代替人进行决定,会实打实的作用于真实世界,不像以前还有人review一下结果再执行操作。
- 外部环境是动态变化的,这就使得用于做决策的输入数据十分的复杂,比如可能有噪音、恶意攻击、未曾考虑到的场景等。算法和系统需要能够识别或者处理好这类的输入数据。
R3: explainable decisions
Build AI systems that can support interactive diagnostic analysis, that faithfully replay past executions, and that can help to determine the features of the input that are responsible for a particular decision, possibly by replaying the decision task against past perturbed inputs. More generally, provide systems support for causal inference.
传统的机器学习对于得到的某个结果,往往不是太好解释这个结果出现的原因。这里需要说明的是,这里的解释,不仅仅指某个结果是怎么计算出来的,而是需要能够说明在某个结果中,那个输入的因素需要对这个结果负责、负多大的责任。
为什么需要结果具备可解释性?原因可能是法律上的,比如无人车出事故了需要进行定责;也可能是技术上的,我们希望能够进行记录并复现某个计算过程,以进行算法或系统的改进。
R4: secure enclaves
Build AI systems that leverage secure enclaves to ensure data confidentiality, user privacy and decision integrity, possibly by splitting the AI system’s code between a minimal code base running within the enclave, and code running outside the enclave. Ensure the code inside the enclave does not leak information, or compromise decision integrity.
通过建立某种隔离屏障,阻断屏障内外的非预期沟通。应用开发者开发程序的时候,可以在屏障内自由的访问数据,在保障数据安全的基础上,也降低了开发成本。另外,由于安全隔离的overhead问题,在现实世界中,我们可能需要拆分应用code,减少进入隔离区的代码粒度。目前Intel的SGX提供了一些类似的机制。
R5: adversarial learning
Build AI systems that are robust against adversarial inputs both during training and prediction (e.g., decision making), possibly by designing new machine learning models and network architectures, leveraging provenance to track down fraudulent data sources, and replaying to redo decision after eliminating the fraudulent sources.
这块主要是指系统需要能够处理好攻击者通过修改输入数据来达到自己目的的行为。在AI系统中,攻击者可以在模型训练阶段(data poisoning attack, on training stage)篡改训练数据,或者在运行阶段篡改决策系统的观察输入(evasion attacks on inference stage)。目前还没有很好的手段能够应对好这两种攻击行为。
R6: shared learning on confidential data
Build AI systems that (1) can learn accross multiple data sources without leaking information from a data source during training or serving, and (2) provide incentives to potentially competing organizations to share their data or models.
在前面提到过,目前许多AI训练需要行业内的众多原本处于”竞争”关系的人贡献出自己的私有数据,并在某个平台内join起来后训练出对所有人都有益的模型,共享训练结果让整个行业进入更高的水准。这就引入来的两个问题:(1) 一个机构不能通过某些渠道得到另一个机构提供的私有数据,否则这个商业模式的基本模式就崩塌了; (2) 需要设计好激励机制,确保机构在贡献自己的私有数据、比不贡献私有数据,能够获得更大的利益,否则这个模式也难以运作起来。
这里的安全问题,主要是为了解决处于”竞争”关系的用户间,共享私有数据可能出现的”信任”问题。
R7: domain specific hardware
- Design domain-specific hardware architectures to improve the performance and reduce power consumptioin of AI applications by orders of magnitude, or enhance the security of these applications.
- Design AI software systems to take advantage of these domain-specific architectures, resource disaggregation architectures, and future non-volatile storage technologies.
目前,计算硬件上的器件数量已经很难像之前那样不断的缩小尺寸,单一芯片上的功率有限,且芯片的体系结构限制了并行化所可能带来的收益(参考Amdahl’s Law),传统的cpu芯片越来越难以跟上AI对计算需求的急剧增长。鉴于这个趋势,越来越多的研究人员將精力转向了针对特定领域优化的芯片架构,追求在具体场景下、將计算能力提高到极致。这方面的典型代表包括近几年很热的TPU、FPGA等。此外,除了研究出这些芯片外,还需要研发配套的、能发挥出这些芯片效能的软件系统。
R8: composable AI systems
Design AI systems and APIs that allow the composition of models and actions in a modular and flexible manner, and develop rich libraries of models and options using these APIs to dramatically simplify the development of AI applications.
在软件行业发展的不同时期,总会出现一些适应该时期的软件架构,以帮助研发人员快速开发相关应用,促成繁荣生态。历史上,这类架构包括诸如microkernel OS、LAMP以及这几年很热的micro-service等。那么,AI时代对应的软件研发架构是啥样?目前还没有明确的结论。
以往的经验表明,模块化是加速研发的重要手段。在这篇文章中,作者认为,AI时代的软件架构需要处理好以下两方面的模块化问题:组合不同模型的能力和组合原子动作的能力。前者负责將众多的模型、算法通过某种描述性语言能够捏合在一起工作,而后者则定义了某些原子动作的接口(如无人驾驶中的”左转”、”右转”等),提高具体领域研发的效率。
R9: cloud-edge systems
Design cloud-edge AI systems that (1) leverage the edge to reduce latency, improve safety and security, and implement intelligent data retention techniques, and (2) leverage the cloud to share data and models across edge devices, train sophisticated computation-intensive models, and take high quality decisions.
由于IoT是AI时代的一个重要落地方向,适应IoT的边缘计算,就逐步变得重要起来。边缘计算需要处理好异构及分布硬件引发的数据存储和计算问题,如需要对计算和数据分级,明确设备、云端需要存储、计算的内容,同时处理好功能、性能以及安全等多方面的问题。这个领域目前还需要摸索合适的系统架构来解决。
About Me
